Psychedelia er et online forum, som vi havde brug for at lave vores egen scraper til at scrape pga. det store antal posts derinde. En manuel gennemlæsning ville være alt for overskuelig, da der fx er 2594 forskellige posts, hvor ordet Ritalin indgår. Målet med scraperen var at lave et program, der kunne hente alle posts ned og herefter give mulighed for at analysere og udtrække posts, som man kunne finde relevante ud fra kriterier som tid eller emne. Det færdige program er blevet brugt til søgning i posts, til at konstruere en tidslinje over antallet af post per måned, et udtræk af posts hvor et eller flere ekstra søgeord indgik som bivirkninger og forskning samt til at finde links, som indgår i sammenhæng med søgeord.
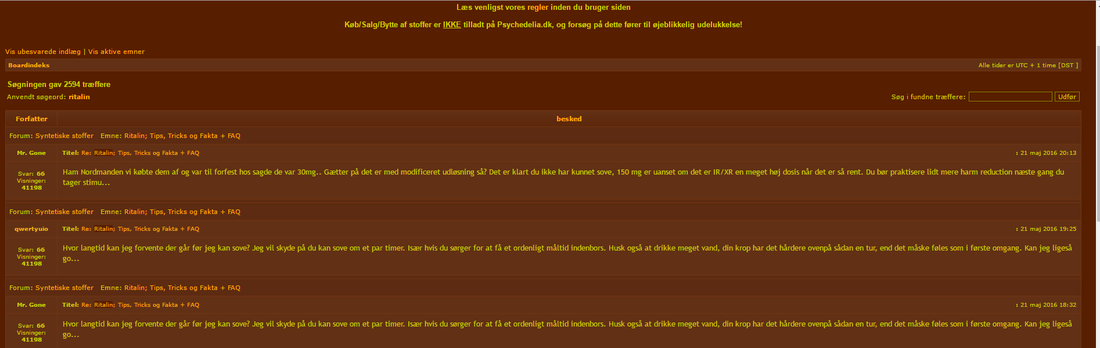
Herunder kan man se, hvordan psychedelia.dk ser ud ved et normalt besøg.
Herunder kan man se, hvordan psychedelia.dk ser ud ved et normalt besøg.
Nedenstående billede viser den html-kode, som hjemmesiden genereres ud fra.

Når man skriver en scraper, er man som udgangspunkt ligeglad med, hvordan hjemmesiden ser ud, når man normalt går ind og besøger den. For at trække data ud skriver man et program, som går ind og læser html-koden for hjemmesiden og trækker det data ud, som man gerne vil have.
Python 3.5 er et programmeringssprog, som vi har valgt, fordi det er et let sprog af skrive i, og der er store muligheder for at tilføje moduler til ens sprog. Blandt andet anvender vi et modul kaldet Beautifulsoup4, som gør ”læsningen” af html koden lettere. Dette modul er i stand til at udtrække al synlig tekst på hjemmesiden og ignorere de programmeringskoder, der ligger omkring. Herefter skal man bare fortælle den, hvilket område man så at sige vil have, at den udtrækker tekst fra.
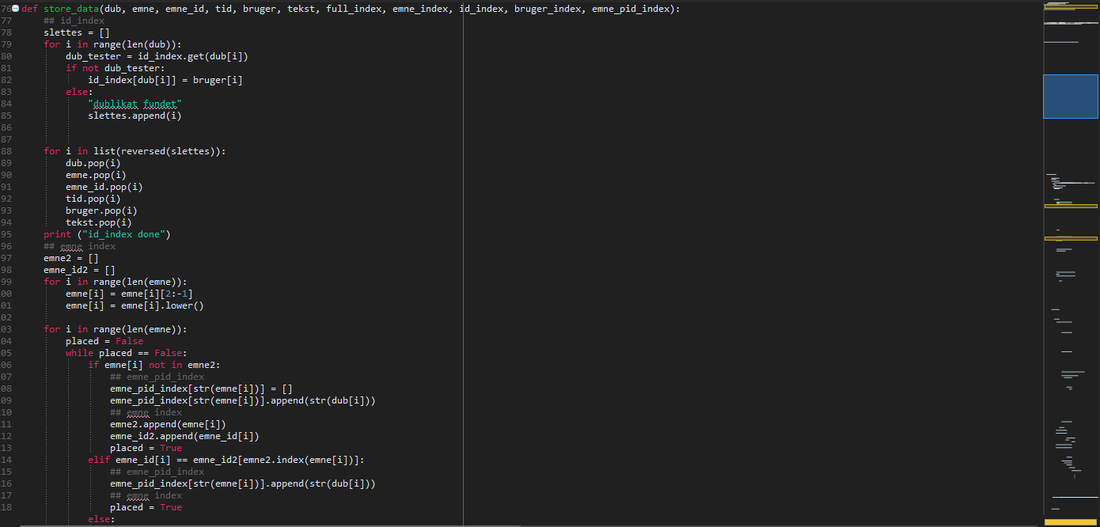
Dette er et udtræk fra det færdige program som viser, hvordan koden ser ud i Python.
Python 3.5 er et programmeringssprog, som vi har valgt, fordi det er et let sprog af skrive i, og der er store muligheder for at tilføje moduler til ens sprog. Blandt andet anvender vi et modul kaldet Beautifulsoup4, som gør ”læsningen” af html koden lettere. Dette modul er i stand til at udtrække al synlig tekst på hjemmesiden og ignorere de programmeringskoder, der ligger omkring. Herefter skal man bare fortælle den, hvilket område man så at sige vil have, at den udtrækker tekst fra.
Dette er et udtræk fra det færdige program som viser, hvordan koden ser ud i Python.
-Synligt på hjemmesiden kan man ved brug af hjemmesidens søgefunktion se postens titel, postens tekst, hvilket emne det er postet under, tidspunktet posten er skrevet samt hvem der har skrevet posten. I html koden kan man dog også se, at hver enkelt post, bruger og emne har et særligt ID knyttet til dem. Her bør det nævnes, at når der her siges "emne" er der tale om forskellige tråde på forummet. Vores mål med scrapingen er at indsamle al denne information undtagen postens titel, da der i mange post ikke var udfyldt nogen titel for posten. Vi ville gerne have postens tekst, tidspunkt den var skrevet, emne den var skrevet under samt hvem der havde skrevet den, fordi det alt sammen er med til at sige noget om posten og den kontekst den er skrevet i. Derudover kan man ud fra brugernavnet i vores Python program finde andre posts af samme bruger. Da hver enkelt bruger har et unik brugernavn, var vi heller ikke nødsaget til at scrape brugernavnets ID. Men både postens id og emne id’et var vigtige at hente ned. Vores scraper er i stand til at scrape over flere omgange og gøre datasættet større. Derfor var det væsentligt, at programmet kunne huske, hvilke posts der allerede eksisterede i datasættet, så der ikke blev tilføjet den samme post flere gange. Emne ID’et var væsentligt, da der godt kan eksistere flere forskellige emner, der deler emnenavn. Ud fra emne ID’et nummerer programmet emnerne, hvis de har samme navn.
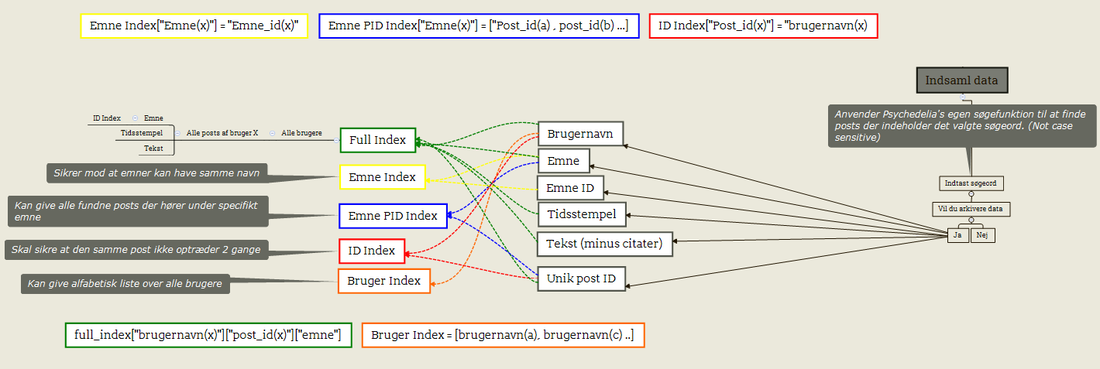
Overstående mindmap illustrerer, hvordan de forskellige posts blev indekseret i vores Python program. Vi blev altså nødt til at lave 5 forskellige indekser. De tre øverste og 2 nederste farvede kasser illustrerer logikken bag de forskellige indekser. De kræver en forståelse af Pythons programmeringssprog for at forstå, men uden at forklare sproget nærmere vises her, hvordan dataen er indrettet i lister og ordbøger i de forskellige indekser.
For at gøre søgning i datasættet lettere valgte vi at lave vores egen søgefunktion til scraperen. På den måde kunne man udtrække et datasæt ud fra et eller flere søgeord og herefter gå ned og nærlæse enkelte post, hvis man ville læse noget fra en bestemt bruger eller post, der hørte under et bestemt emne.
For at gøre søgning i datasættet lettere valgte vi at lave vores egen søgefunktion til scraperen. På den måde kunne man udtrække et datasæt ud fra et eller flere søgeord og herefter gå ned og nærlæse enkelte post, hvis man ville læse noget fra en bestemt bruger eller post, der hørte under et bestemt emne.
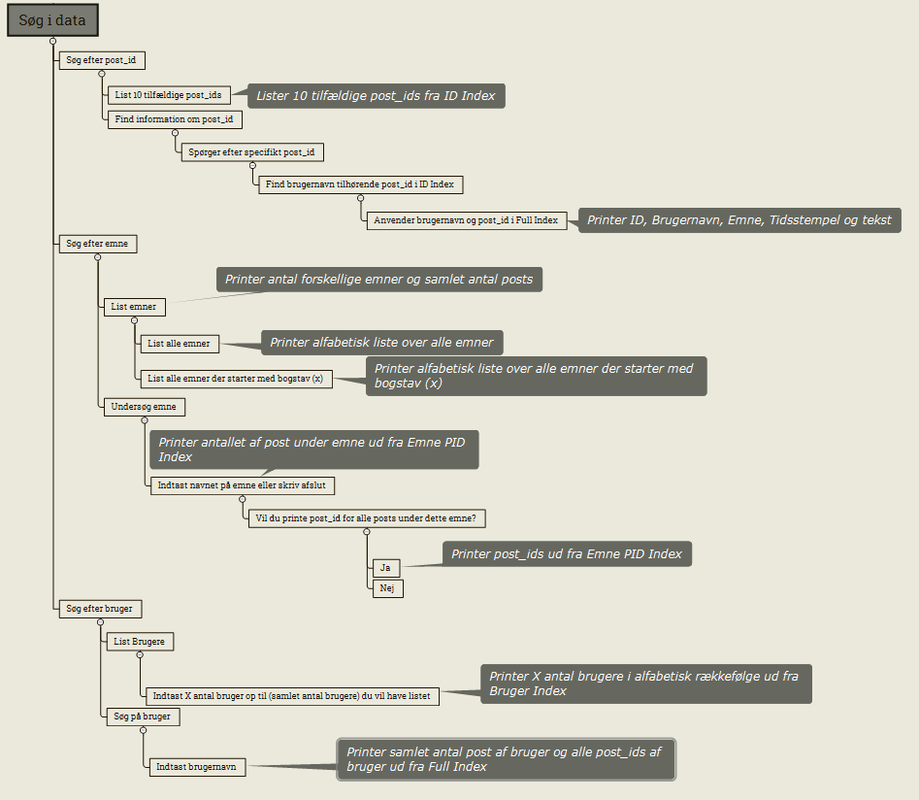
I overstående mindmap illustreres logikken bag denne søgefunktion i vores Python-program samt hvilke muligheder for søgning, man kan lave.
Ud over dataindsamling og søgefunktion har vi skrevet 3 forskellige analysemetoder til vores Python program.
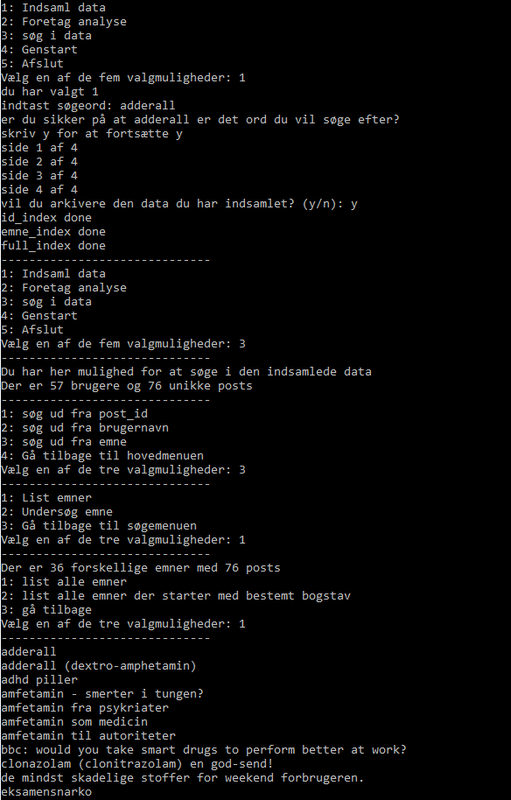
Her afslutningsvis er der et billede af, hvordan programmet ser ud, når man kører det.
Ud over dataindsamling og søgefunktion har vi skrevet 3 forskellige analysemetoder til vores Python program.
- Den første analysemetode genererer en tekstfil, hvor antallet af post pr. måned indskrives. Denne analysemetode er anvendt i vores kortlægning for at se på forskellige udsving i, hvornår der skrives om forskellige emner.
- Den anden analysemetode er et udtræk af posts fra datasættet, hvor der indgår links. Dette er gjort ved søge i datasættet efter posts hvor ”.dk”, ”.com”, ”.org”, ”.net” ”.gov”, ”http” eller ”www” indgår som tekst i posten. Herefter generes der en tekstfil, hvor alle links er listet. Disse links har vi blandt andet brugt i vores Issue og Navicrawler analyser.
- Den tredje analysemetode finder posts, hvor et eller flere søgeord indgår og generer tekstfiler, hvor postens tekst indgår. Dette har vi brugt til at finde posts, som indeholder et eller flere søgeord som ”forskning”, ”afhængighed” og ”bivirkninger” - i dette tilfælde for at finde posts om Ritalin, der havde et mere videnskabeligt indhold og ikke fx handlede om, hvor man kan købe Ritalin.
Her afslutningsvis er der et billede af, hvordan programmet ser ud, når man kører det.